第一章:从 0 到 100 万用户的扩展
一、系统设计学习重点
和面试官聊系统设计,最重要的不是背架构图,而是能表现出这几种能力:
1. 能先问清楚需求
面向 C 端还是 B 端?
日活多少?
读多写多还是写多读少?
强一致还是最终一致?
延迟、可用性、成本哪个优先?
2. 能搭一个主链路
用户请求怎么进来?
API 服务怎么处理?
数据怎么存?
缓存怎么加?
消息队列放在哪里?
哪些地方会成为瓶颈?
3. 能讲权衡
MySQL vs NoSQL
同步 vs 异步
推模式 vs 拉模式
强一致 vs 最终一致
本地缓存 vs 分布式缓存
分库分表 vs 读写分离
4. 能结合自己的项目聊
你做过:RAG Agent 文档解析 压测 Milvus Redis MySQL 并发测试
所以你读这本书时,要主动问:
“这个设计思想,能不能迁移到我的项目里?”
1. 从 0 到 100 万用户的扩展
1.1 单服务器配置
Web 服务的流量有两个:
1. Web 应用端
使用 Java / Python 来处理业务逻辑、数据存储等
使用客户端 HTML 以及 JavaScript 来展示内容
2. 移动应用端
JSON 作为 API 响应格式
1.2 数据库
一台服务器用于处理 Web 应用和移动应用的流量,一台服务器用作数据库。
也就是:
把处理 Web 应用 / 移动应用流量的服务器和数据库服务器分开。
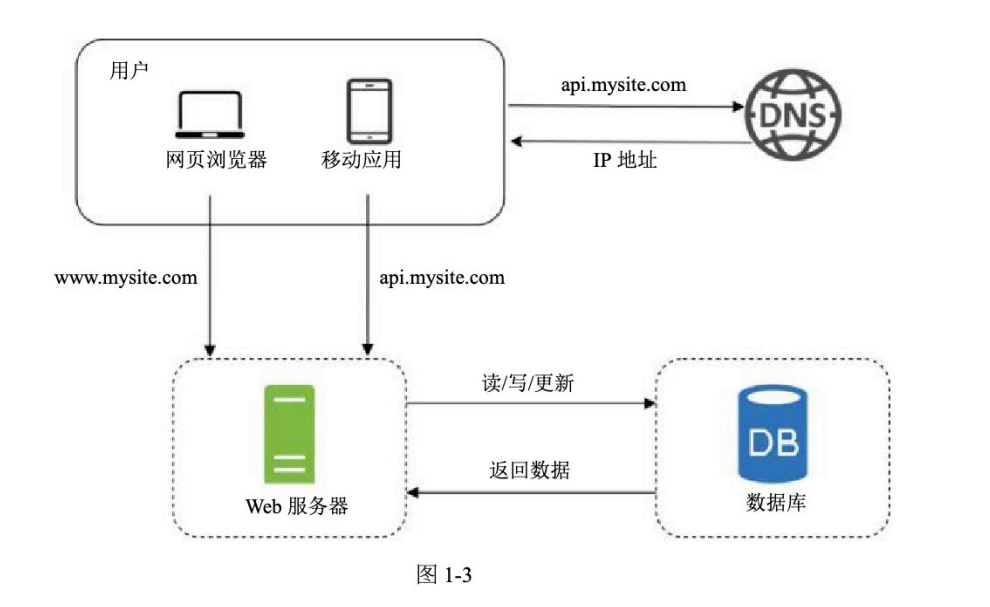
用户通过
www.mysite.com或api.mysite.com访问服务Web 服务器处理请求
数据库单独部署
Web 服务器和数据库之间有读 / 写 / 更新交互
数据库类型
关系型数据库使用表和行来存储数据。
非关系型数据库通过下面几种方式存储数据:
键值存储
图存储
列存储
文档存储
数据库的选择:
一般情况下使用关系型数据库。
有如下场景,比较适合非关系型数据库:
1. 应用只能接受非常低的时延
2. 应用中的数据是非结构化的,数据之间没有明确的关系
1.3 纵向扩展与横向扩展
纵向扩展
纵向扩展指的是:
提升服务器的能力
比如:
增加 CPU
增加内存
增加磁盘
提升单机性能
横向扩展
横向扩展指的是:
增加更多的服务器
1.4 负载均衡器
负载均衡器的作用:
进行流量分发,把海量用户的流量访问,均衡地分配给每一台服务器。
1.5 数据库的复制
数据库集群一般是:
一个主数据库
若干从数据库
主数据库处理写请求,并将修改的信息更新到从数据库中。
从数据库处理读请求。
设置多个读数据库可以分担读压力。
整体过程:
建立负载均衡器和用户端的连接
HTTP 请求通过负载均衡器转发到其中一个服务器上
服务器在从库中读数据
服务器在主库中修改数据,并同步更新到其他从库上
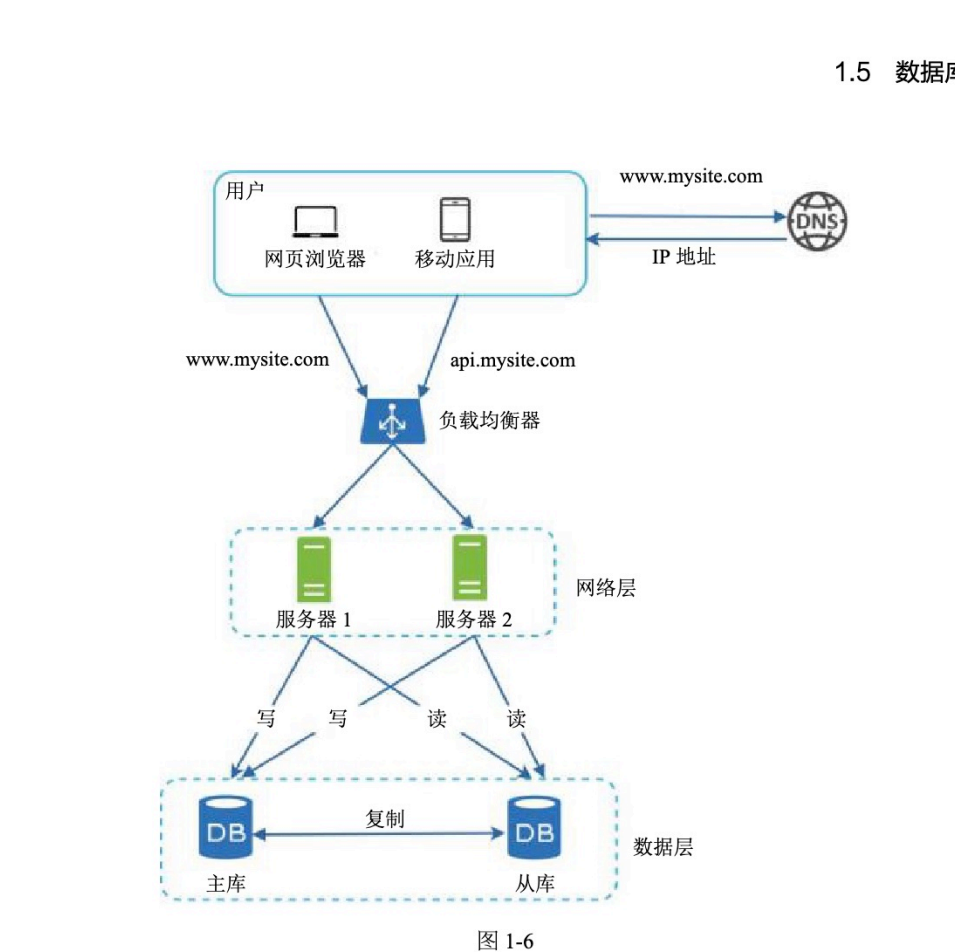
图中重点体现:
用户请求先到负载均衡器
负载均衡器分发请求到不同服务器
写请求进入主库
读请求进入从库
主库向从库复制数据
1.6 缓存
什么时候应该使用缓存?
当数据满足下面特点时,适合使用缓存:
对数据的读操作非常频繁,而修改不是很频繁。
缓存策略包括:
过期策略
一致性
减轻出错的影响
驱逐策略
1. 过期策略
缓存中的数据不能永久保存,需要设置过期时间。
2. 一致性
修改数据的事务和缓存数据的事务,不是同一个事务,就会发生不一致现象。
3. 减轻出错的影响
可以采用:
单点缓存服务 → 多点缓存服务
将一部分内存给缓存容量,允许一定的超量
4. 驱逐策略
缓存容量有限,需要有驱逐策略。
单点故障
单点故障指的是:
系统中的某一部分,如果它出现故障,整个系统就不能工作。
图片描述:缓存读取流程
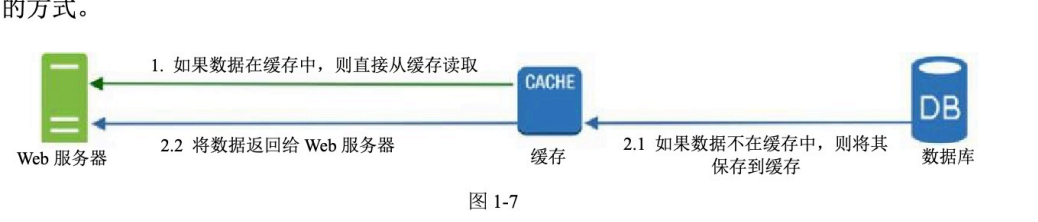
具体流程为:
1. 如果数据在缓存中,直接从缓存中读取
2. 如果数据不在缓存中,到数据库中读取
3. 读取后将数据写入缓存
1.7 内容分发网络
CDN 是一个大型的缓存系统。
它用来缓存用户高频访问的静态资源,让用户从离自己更近的节点获取资源,而不是每次都去源站服务器拉取。
图片描述:CDN 访问流程
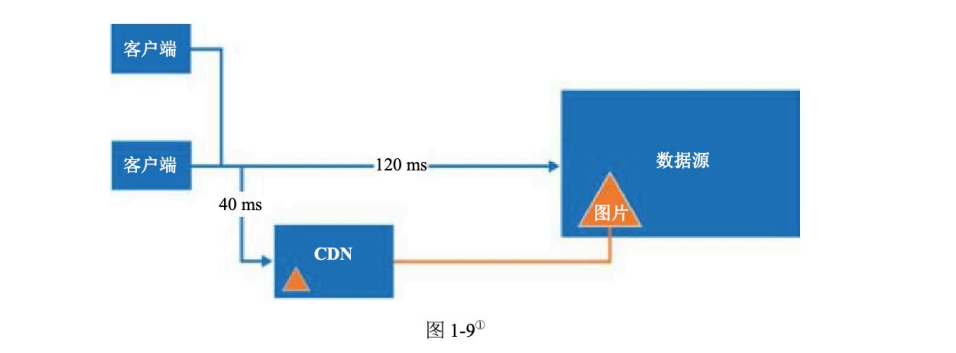
客户端请求静态资源
如果 CDN 有缓存,直接返回
如果 CDN 没有缓存,则回源站拉取
拉取后缓存到 CDN,再返回给用户
1.8 无状态网络层
1.8.1 有状态架构
有状态的服务器会处理客户端发来的一个个请求,并记下客户端的状态数据。
无状态架构的服务器,不会记录客户端的状态数据。
有状态架构的问题
用户 A 的会话数据和个人资料会被存储到服务器 1 上。
为了能让用户 A 访问到自己的资料和信息,必须要求用户 A 发送的 HTTP 请求精准地打到服务器 1 上。
如何将来自同一客户端的所有请求都发送给同一个服务器?
需要使用负载均衡器的粘性会话功能。
但是这样会:
增加成本
添加服务器变困难
移除服务器变困难
服务器故障更难处理
图片描述:有状态架构
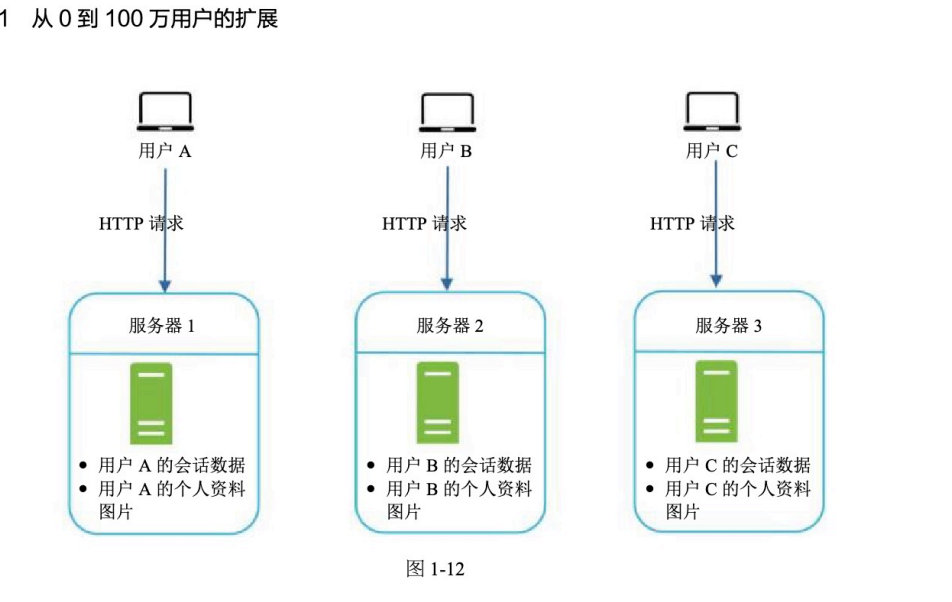
每个服务器内部保存对应用户的数据,例如:
服务器1:用户A的会话数据、用户A的个人资料、图片
服务器2:用户B的会话数据、用户B的个人资料、图片
服务器3:用户C的会话数据、用户C的个人资料、图片
1.8.2 无状态架构
无状态架构中,服务器不保存用户状态。
用户请求可以发送到任意 Web 服务器。
Web 服务器需要状态数据时,从共享数据存储中获取。
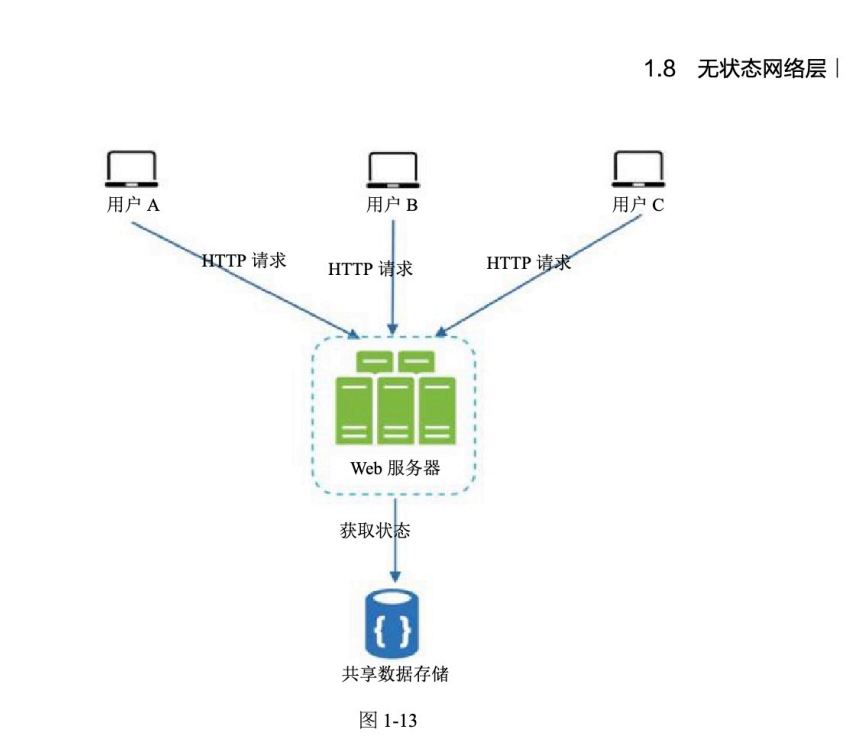
多个用户请求可以打到任意 Web 服务器
Web 服务器不保存用户状态
用户状态统一放到共享数据存储中
图片描述:加入无状态网络层后的系统设计
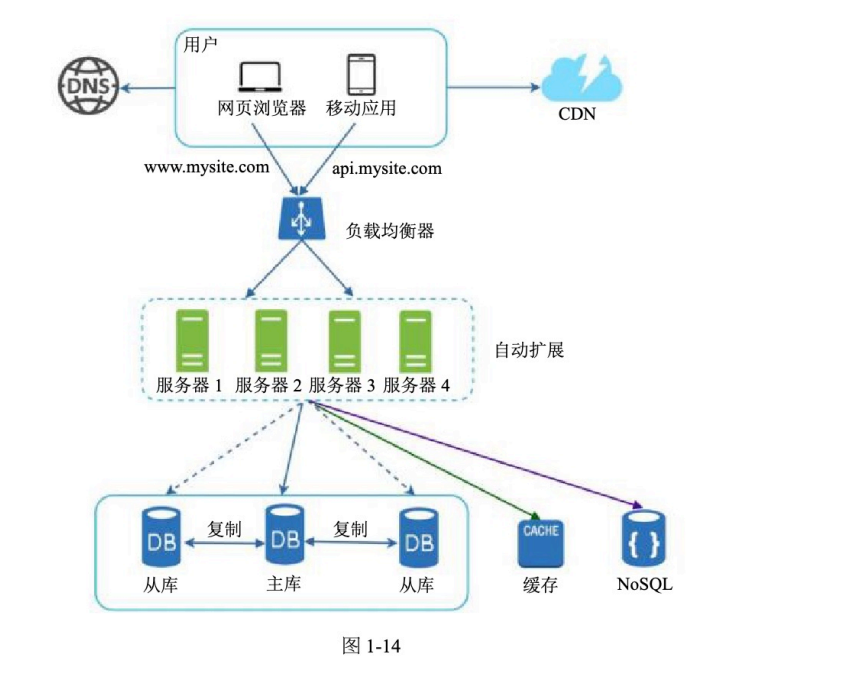
CDN 用于静态资源
负载均衡器分发请求
Web 层可以自动扩展
数据层包括数据库、缓存、NoSQL
Web 层保持无状态
1.9 数据中心
数据中心是什么?
数据中心可以理解为:
机房。
为什么要用数据中心?
主要有两个原因:
就近访问,降低延迟
容灾
单数据中心
单数据中心指的是:
系统部署在一个机房中。
流程如下:
用户
↓
DNS / CDN
↓
动态请求进入数据中心
↓
负载均衡
↓
Web 服务
↓
缓存 / 数据库 / 消息队列
↓
返回结果
多数据中心
当业务非常大,用户分布在多个地区,就需要部署多个数据中心。
多数据中心的好处:
延迟更低
容灾性更好
难点:
数据同步复杂
一致性更难
成本更高
1.10 消息队列:重点
消息队列是一个任务缓冲。
Web 服务器把暂时不需要立刻完成的任务放进去,后面的 Worker 慢慢处理。
消息队列的作用
1. 异步处理
例如:
用户注册成功
发送问候邮件或者短信
这些任务可以异步处理,不需要阻塞主流程。
2. 削峰填谷
假设突然来了 100 万个请求。
如果直接把所有任务打到下游服务或者数据库,会把系统打崩。
这时可以先放到消息队列中,再慢慢消费。
3. 解耦系统
无消息队列时:
下单系统 和 库存系统两个系统强绑定
有消息队列时:
下单系统 → 消息队列 → 库存系统
下单系统只管发消息,其他系统自己消费。
1.11 记录日志、收集指标与自动化
指标
用户的指标包括:
1. 主机级别的指标
例如:
CPU
内存
磁盘 IO 等
2. 聚合级别指标
例如:
整个数据库层的性能
整个缓存层的性能
3. 关键业务指标
例如:
每日活跃用户数
留存率
收益等
自动化
一个比较大的系统,使用自动化工具提高生产力十分重要。
持续集成
每次代码 check in 的时候,需要自动化工具进行审核。
构建、测试和部署等流程也需要自动化。
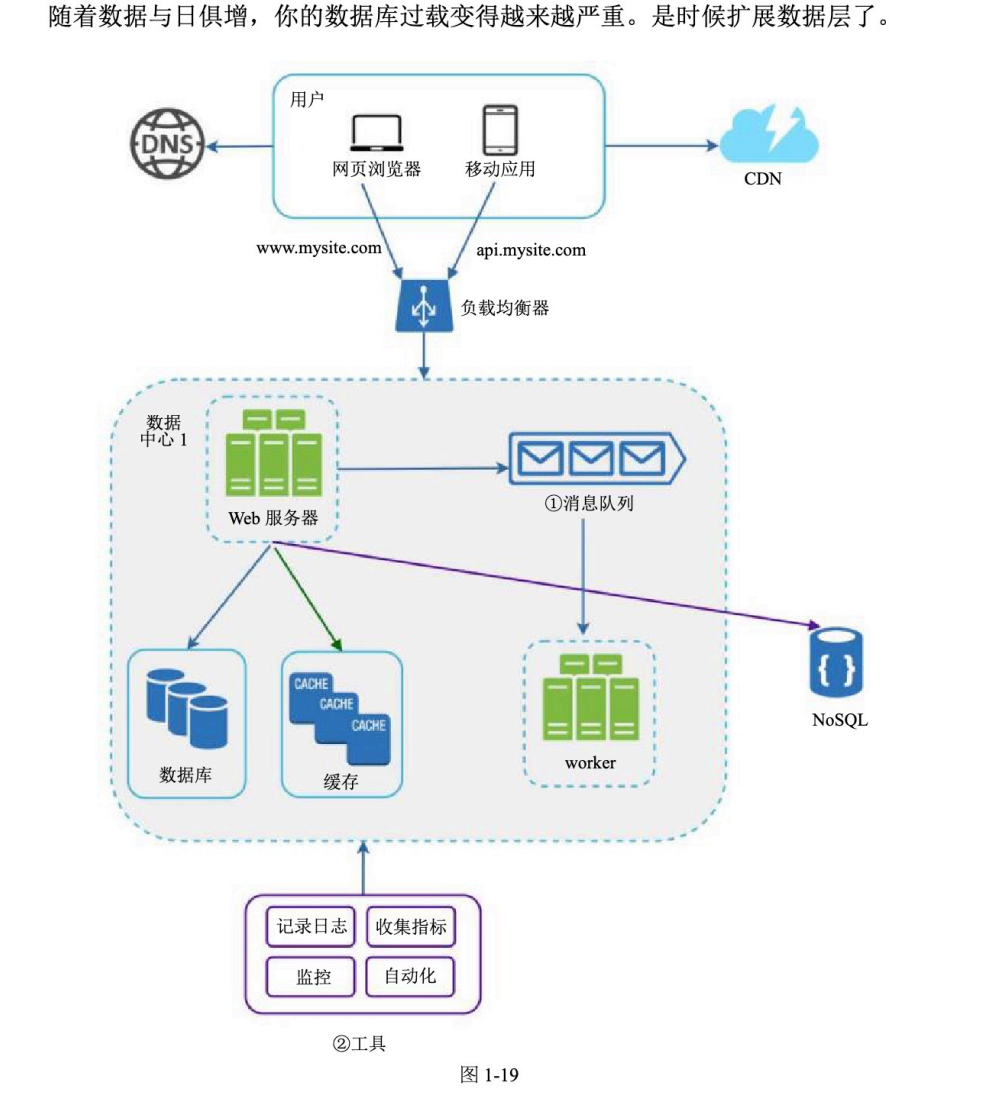
整体访问流程
用户
↓
DNS
↓
CDN / 负载均衡器
↓
Web 服务器
↓
缓存 / 数据库 / NoSQL / 消息队列
图片描述:百万用户系统整体架构
访问静态资源
用户请求静态资源
↓
DNS 把请求导向 CDN
↓
CDN 判断自己有没有缓存
↓
有:直接返回
↓
没有:回源站拉取,再缓存,再返回
访问动态接口
例如:用户查看商品详情。
读数据流程:
用户请求 api.mysite.com
↓
DNS 解析域名
↓
请求到负载均衡器
↓
负载均衡器选择一台 Web 服务器
↓
Web 服务器处理业务逻辑
↓
访问缓存 / 数据库 / NoSQL
↓
返回结果给用户
写数据
例如:用户下单。
写数据流程:
用户提交订单
↓
负载均衡器
↓
Web 服务器
↓
写入数据库
↓
发送一条消息到消息队列
↓
立即返回:下单成功
Worker 队列慢慢处理:
消息队列
↓
Worker 消费消息
↓
发送短信
↓
发邮件
↓
扣库存
↓
生成报表
↓
推送通知
1.11 数据库扩展
1. 数据库为什么要扩展?
随着用户数量和数据量增长,单个数据库会遇到瓶颈。
常见瓶颈包括:
CPU
内存
磁盘
IO
单表数据量
所以需要扩展数据库层。
2. 数据库扩展的两种方式
1. 纵向扩展
定义:
给数据库机器增加 CPU、内存、SSD 等硬件。
优点:
简单
改动小
缺点:
单点故障风险仍然存在
硬件有上限
2. 横向扩展
定义:
把数据库拆到多台机器上。
优点:
容量变大
单表更小
写压力得到分散
缺点:
跨库 Join 困难
跨库事务复杂
3. 怎么做到分片?
选取一个字段,叫做:
shard key
中文叫:
分片键
4. 分片键为什么非常重要?
分片键决定一个数据应该落到哪个数据库。
例如:
用户系统按照 user_id 分片
订单系统按照 user_id 或者 order_id 分片
5. 分片带来的新问题
1. 分片之后,跨库连接查询困难
业务场景:
想通过 order_id 查询订单,同时还想拿到这个订单对应的用户信息。
这时候,订单数据和用户数据不在同一个数据库中,查询就比较困难。
2. 分片之后,跨库事务复杂
业务场景:
分库之后:
订单表在数据库1
库存表在数据库2
支付表在数据库3
创建订单这个事务需要:
1. 在数据库1中插入订单
2. 在数据库2中扣减库存
3. 在数据库3中插入支付记录
如果前两个操作成功,第三个操作失败,系统就进入了不一致的状态。
单库可以保证原子性,但多库中各个数据库是独立的,很难保证原子性。
解决方案:
尽量让事务落在同一个分片
比如订单、支付记录,按照order_id或者user_id分到同一个库中。最终一致性
通过消息队列来异步处理,只做最后的校验,允许短时间不一致。
3. 扩容迁移复杂
原来 4 个分片,现在变成 8 个分片。
取模数量一变,大量数据的归属都会发生变化。
这会导致:
海量的数据迁移,而且不能停机。
1.13 百万用户量系统设计
扩展系统以支持百万量级用户,需要下面几个技术点:
让网络层无状态
让每一层都有冗余
尽量多缓存数据
支持多个数据中心
用 CDN 来静态加载资源
通过分片来扩展数据层
把不同的架构分成不同的服务
监控系统并使用自动化工具